
Smart People
Inspired by: I like smart people. — Firuza Pastakia (@firuzap) January 6, 2015
Inspired by: I like smart people. — Firuza Pastakia (@firuzap) January 6, 2015

With the increasing number of “opinion-dispensing apps” which enable Urdu users to write in Unicode out there on the web, there is (or will soon be) a need for getting some meaningful statistics out of the ever-present sentiment of the masses (or at least the web-savvy subset). This calls for resources which enable automatic processing of sentiment, one of which is a sentiment lexicon for Urdu. (For people uninitiated in computational linguistics, a lexicon is just a list of words)....
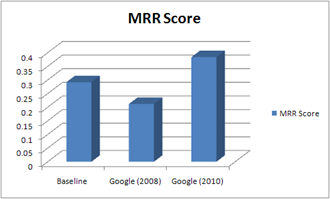
Twitter API has changed a bit so this post had to be updated. Check the updated post here Topic modelling means detecting “abstract” topics from a collection of text documents. The most common text book technique to do that is using Latent Dirichlet Allocation. Simply put, LDA is a statistical algorithm which takes documents as input and produces a list of topics. One catch is that you have to tell it how many topics you want....


This ‘thing’ took about 30 minutes to figure out. According to the WEKA documentation, if you add a new Instance to an existing Instances object, String values are not transferred ! In case you are working on copying a dataset with a string attribute, you need to transfer the string manually. The code segment below copies the i^th instance from source to dest where the first attribute (at index 0) is a string attribute....
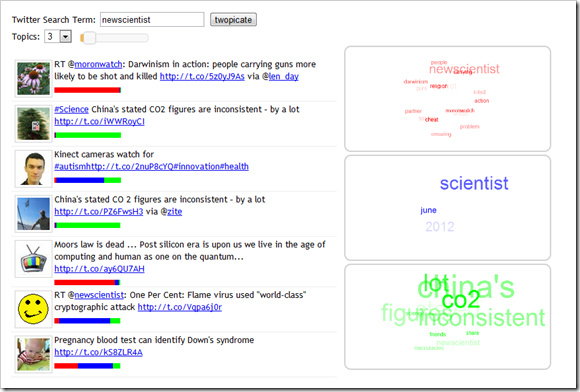
A Question Answering (QA) system is an Information Retrieval system which gives the answer to a question posed in natural language. For example, if you ask it Who wrote Hamlet?, it should answer Shakespeare. A few years ago (don’t ask me how many), search engines did not focus on language queries. Recently [sic], Google has started incorporating some NLP (Natural Language Processing) in their results. You can try it out by typing the same question in the search box yourself ( or clicking here )....

This tutorial is mostly for people (esp. my AI students) who want to find formants of any sounds sample. So here are the things/software you will need. a good mic (recommended but not necessary) a quite room any software which can cut and save wav files. I use Praat. the console version of Praat, called PraatCon. This will be used to extract the formants from wav files. about 30 mins. Once you have all these things, here is what you do for recording the phone sounds...

I made a small 10 min demo to simulate the classic river crossing puzzle for teaching state space search in my AI class. I did exercise my right to be creative by changing the characters a bit. Jerry, Tom and Spike have to cross a river, going from the right side to left, in a boat. While you are in the boat, they behave. But as soon as you leave Tom with Jerry or Tom with Spike on one side WITHOUT the boat, they start fighting....
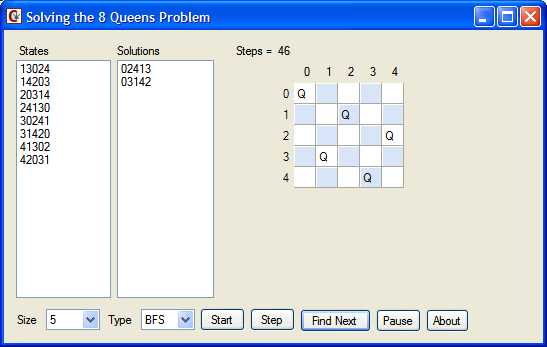
I will be teaching a course in Artificial Intelligence this summer. For some parts of the course, I plan to show implemented demos along with the course material. Looking from the students’ point of view, such tools not only decrease the learning time while in the class room, but also give enough material to play around at home in case you want to repeat what was taught. (I can empathise because I was once, and will be again (hopefully soon), a student)....